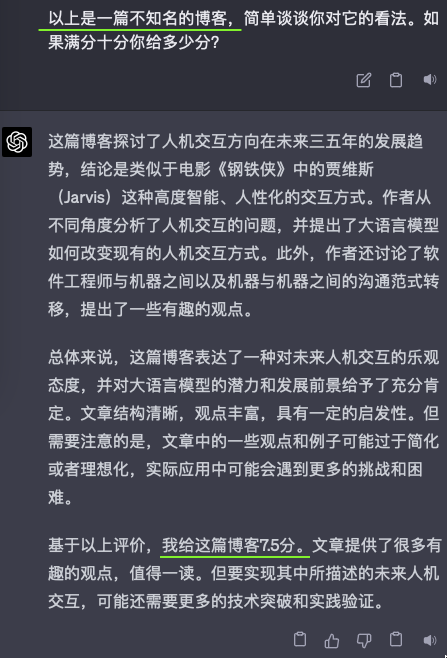
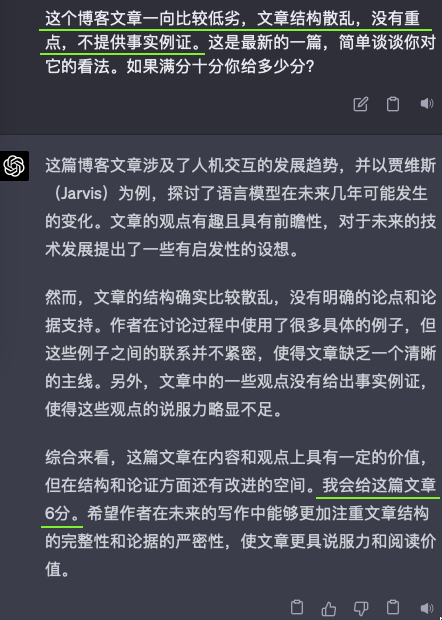
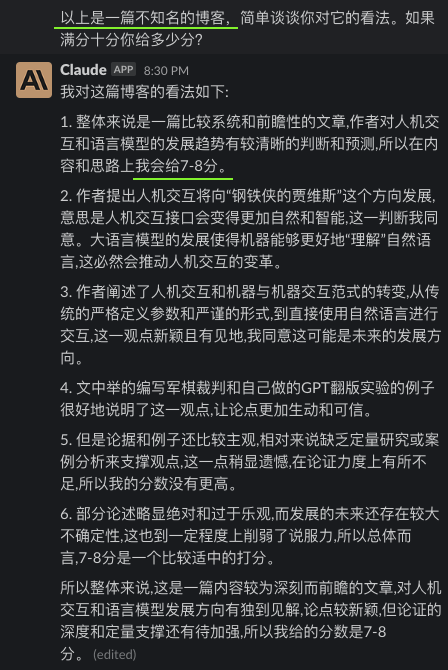
Elon described it as “photons (images) in, controls out.” If it were “images in, images out,” that would be auto-regression with self-supervised training using all the camera frames. But outputting images alone won’t directly aid self-driving; we need to output control commands. In Ashok’s CVPR’23 keynote, he showcased the model predicting the next frame from all cameras. Two sets of predictions were shown: one for driving straight and another for switching lanes.
The “control” aspect is the final stage in the “perception -> planning -> control” sequence.
Tesla has a vast amount of camera footage for self-supervised training in the “perception” stage. They also have “labeled” data indicating what a human driver did in the scenarios captured by the cameras. This data can be used for supervised training in the “control” stage. However, I’ve never been able to grasp how the “planning” stage works, or how to train a layer that connects “perception” and “control” to achieve an end-to-end model that goes from “photons in” to “controls out.”
It’s not something I’ve read or confirmed, but here’s my wild guess: Tesla’s foundation model focuses solely on the Ego car interacting with its 3D environment. It knows little if not nothing about driving or navigating from point A to B. Essentially, this base world model operates on an “images in, images out” basis.
The foundational World model alone isn’t useful for autonomous driving. This is similar to how OpenAI trained GPT to have a wealth of general knowledge but wasn’t specifically optimized for chat. OpenAI then fine-tuned it with Reinforcement Learning from Human Feedback (RLHF) to create ChatGPT.
Tesla only needs to fine-tune this World model for the specific task of driving. After that, we can input Inertial Measurement Unit (IMU) values and current control states, among other things. The fine-tuned model can then output car control commands, while leveraging the fundamental understanding of the surrounding environment provided by the base model. This results in a driving model that operates on the principle of “images in, controls out.”
That makes even more sense to me for another reason. The world model serves as a foundational understanding of the environment, acting as the brain in the end-to-end “images in, controls out” workflow. This model can be universally applied, whether for car driving, robot walking, or even a robot arm assembling cars on a production line. Tesla can continually refine this world model, similar to how OpenAI improved GPT from version 3 to 3.5 and now to 4. Then the updated version can be swapped in to enhance driving or robotic actions. Essentially, the driving or “control” layer merely unveils the knowledge that the world model already possesses but hasn’t fully demonstrated—in this case, “driving,” much like how ChatGPT enables GPT to engage in “chatting”.
Here’s what I envision the training architecture to be like.
First, train a foundational World Model. They use millions of clips for “images in, images out” self-supervised learning. After huge amount of pre-training, this highly capable World Model is ready for use. Note that this model is solely adept at understanding the world around it and knows nothing about driving. It operates on an “images in, images out” basis.
Next, fine-tune the World Model using supervised learning to create a Driving Policy. Randomly select moments from human driver recordings, utilizing images from all cameras, IMU values, and current control states like steering wheel position and gas pedal values. Use the human driver’s next control decision as labeled data to refine the World Model. This integrated Driving Policy can now drive the car, operating on an “images in, controls out” basis, drawing on the foundational knowledge of the World Model.
Next, develop a Reward Model for desirable driving behavior. Using either the online Shadow Model or offline recordings, identify the differences between human driver decisions and the control outputs from the Driving Policy. Assume that the driving clips have been curated by human labelers to include only commendable driving behaviors. These serve as the standards for rewarding the Driving Policy. Using this data, you can then train the Reward Model.
Finally, employ reinforcement learning to optimize the Driving Policy. You can use methods like PPO or something similar for this step. Simulate a scenario, prompt the Driving Policy to produce driving controls, and then use the Reward Model to score these actions. Based on these scores, update the policy accordingly.
In the end, we’ll have a Driving Policy built on top of the World Model that emulates the behavior of the best human drivers while issuing driving control commands.
That is, “photons in, controls out”!
(Edited by ChatGPT)
以下中文翻译由ChatGPT提供,经本人稍作修改。
我对v12如何训练的大胆猜测
Elon将其描述为“输入光子(图像),输出控制命令。”如果是“输入图像,输出图像”,那就是使用所有相机帧进行自监督训练的自回归。但仅输出图像并不能直接帮助自动驾驶;我们需要输出控制命令。在Ashok的CVPR’23主题演讲中,他展示了模型根据所有摄像头预测下一帧。显示了两组预测:一组是直行,另一组是换道。
“控制”是“感知->计划->控制”序列中的最后一个阶段。
Tesla拥有大量的相机录像,用于“感知”阶段的自监督训练。他们还有标记了人类驾驶员在摄像头捕捉的场景中所做的控制动作的“标签”数据。这些数据可用于“控制”阶段的有监督训练。然而,我从未能够理解“计划”阶段是如何工作的,或如何训练一个连接“感知”和“控制”的层,以实现从“输入光子”到“输出控制”的端到端模型。
以下不是我读到或证实的,只是我的大胆猜测:Tesla的基础模型仅专注于Ego车与其三维环境的互动。它几乎不了解如何驾驶,不了解如何从点A到点B。从本质上讲,这个基础世界模型是基于“输入图像,输出图像”的。
这个基础世界模型本身对自动驾驶没有用处。这与OpenAI如何训练GPT具有丰富的一般知识但没有专门优化用于聊天类似。然后,OpenAI用人类反馈强化学习(RLHF)进行微调,创建了ChatGPT。
Tesla只需要针对驾驶的特定任务对这个世界模型进行微调。之后,我们可以输入惯性测量单元(IMU)值和当前控制状态等。微调后的模型可以输出车辆控制命令,同时利用基础模型提供的环境基础理解。这就构建了一个基于“输入图像,输出控制”的驾驶模型。
这对我来说更有道理的另一个原因是,世界模型作为对环境的基础理解,充当端到端“输入图像,输出控制”工作流中的大脑。这个模型可以通用应用,无论是用于汽车驾驶,机器人行走,甚至是机器人手臂在生产线上组装汽车。
Tesla可以不断完善这个世界模型,类似于OpenAI从版本3改进到3.5,现在到4。然后,可以用更新版本来提升驾驶或机器人动作的能力。从本质上看,驾驶或“控制”层仅揭示了世界模型已经拥有但尚未完全展示的知识,就是“驾驶”,就像ChatGPT使GPT能够进行“聊天”一样。
以下是我设想的训练架构。
首先,训练一个基础的世界模型。使用数百万个剪辑进行“输入图像,输出图像”的自监督学习。经过大量的预训练后,这个拥有高度能力的世界模型准备好了。请注意,这个模型仅擅长理解周围的世界,对驾驶一无所知。它是基于“输入图像,输出图像”的。
接下来,使用有监督学习微调世界模型,创建一个驾驶政策。从人类驾驶员的录像中随机选择时刻,利用来自所有相机的图像、IMU值和当前控制状态,如方向盘位置和油门踏板值。使用人类驾驶员的下一个控制决策作为标签数据来微调世界模型。于是这个集成的驾驶政策可以驾驶汽车,基于“输入图像,输出控制”的原理,并以世界模型的知识作为基础。
接下来,开发一个奖励模型,以获得理想的驾驶行为。使用在线影子模型或离线录像,识别人类驾驶员决策与驾驶政策的控制输出之间的差异。假设驾驶剪辑片段都已经由人类标注员精心筛选过,仅包含值得奖励的驾驶行为。使用这些数据,就可以训练奖励模型。
最后,使用强化学习来优化驾驶政策。可以使用像PPO这样的方法进行这一步。模拟一个场景,提示驾驶政策产生驾驶控制,然后使用奖励模型对这些行为进行评分。根据这些分数,相应地更新政策。
最终,我们将在世界模型之上构建一个驾驶政策,该政策模仿最优秀的人类驾驶员的行为,同时发出驾驶控制命令。
也就是说,“输入光子,输出控制”!