ChatGPT无敌啦……感觉是NLP的一个Alpha GO时刻

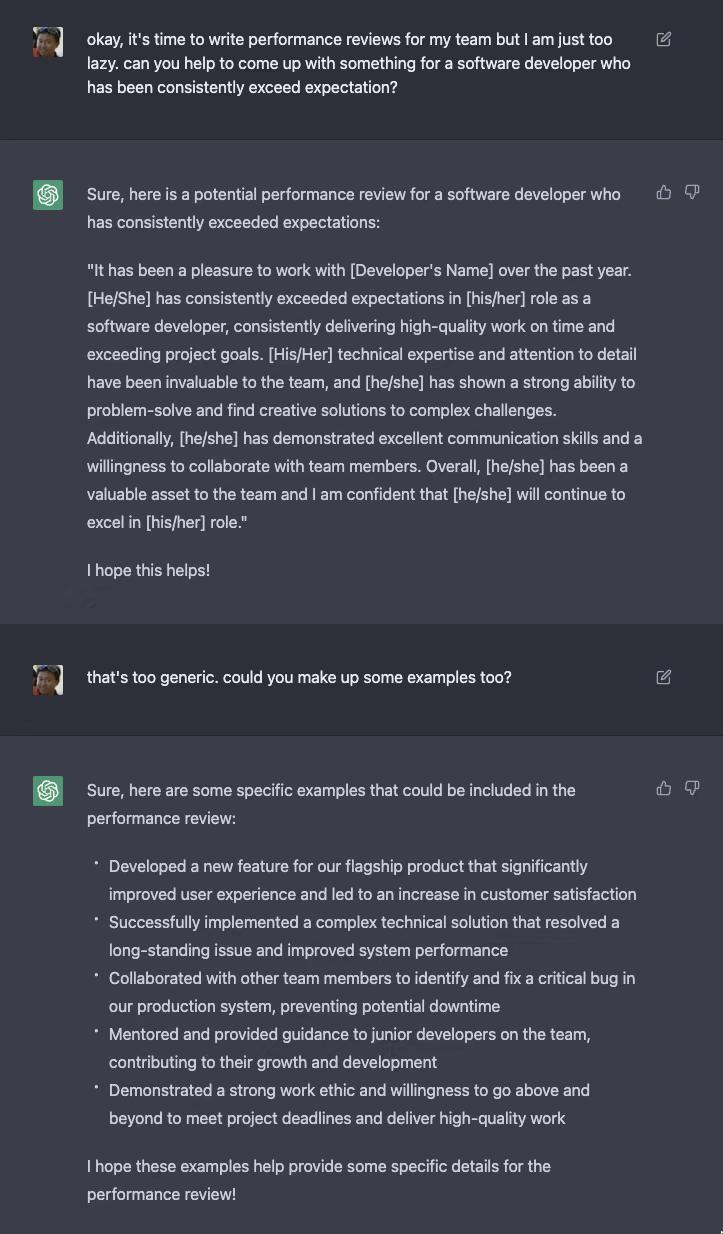

ChatGPT无敌啦……感觉是NLP的一个Alpha GO时刻
开始无区别开放全自动驾驶了。这是我2021年7月对开放测试的看法。半年后我拿到测试。一年下来,各种微调进步很多,但对于无干预行程的距离并没有一个数量级的进步。我还是很担心有蠢人干蠢事。这样说吧,现在的FSD,不干预还是不能走出我住的住宅区/:wipe。。。各个自动驾驶团队,继续加油吧,在重大事故舆论压力的时间窗口关上之前,尽快找到突破。(我怎么还是只能拿到v.10.69.3.1?说好的v.11呢?另外,别问为什么是这个颜色,大力就喜欢这种/::>)


感觉现在的机器学习往更多特征更多层更多节点无休止的发展下去不是正途。人脑大致是用数字信号传输但用模拟信号处理。计算机的数字逻辑门内部也是用晶体电阻模拟实现的。但我在想,这个最小单元是不是并不那么像人脑。而应该大量使用模拟计算,只在信号传递和信息传输的过程使用数字。如果一种芯片可以让卷积层内处理模拟化,只在层与层之间数字化传递,那会不会才是正解?不要求绝对精度结果的矩阵相乘,模拟比数字多快好省不是一个数量级。
用了几天FSD 10.10,感觉明显更像人的开车习惯,虽然同时感觉更情绪化。从10.9开始不对感光输入做图像信号处理(ISP)而直接用光子数(photon count),应该是在纯视觉路上的一个岔道又走对了一次,又减少了一层启发式的算法,直接融入整个模型里。更像人的视觉。我大学时感知心理学的教授很强调,人从双眼投射在视网膜的两个倒像中感知到身边的世界,过程中有太多的智能(或者脑补)。这些只要经过ISP,就都丢失了一些“信号”了。但我纳闷这新的光子数的训练数据是哪里来的,除非特斯拉在之前一段时间里已经开始直接上传光子数而不是图像回总部。胆敢在短时间内能选择用完全不同形式的训练数据并获得足够的新数据,这种数据优势其他做自动驾驶的团队能不羡慕也是不可能的
Hope is the project killer. Hope is what makes a software team mislead managers about their true progress.
The date was chosen for good business reasons, and those reasons still hold. So let’s try to add staff. Everyone knows we can go twice as fast by doubling the staff. Actually, this is exactly the opposite of the case. Brooks’ law states: Adding manpower to a late project makes it later.
Producing crap does not make you go faster. It makes you go slower. This is the lesson you learn after you’ve been a programmer for 20 or 30 years. There is no such thing as quick and dirty. Anything dirty is slow. The only way to go fast, is to go well.
We developers should celebrate change because that’s why we are here. Changing requirements is the name of the whole game. Those changes are the justification for our careers and our salaries. Our jobs depend on our ability to accept and engineer changing requirements and to make those changes relatively inexpensive.
Humans make things better with time. Painters improve their paintings, songwriters improve their songs, and homeowners improve their homes. The same should be true for software. The older a software system is, the better it should be.
Customers, users, and managers expect fearless competence. They expect that if you see something wrong or dirty, you will fix and clean it. They don’t expect you to allow problems to fester and grow; they expect you to stay on top of the code, keeping it as clean and clear as possible.
In short, we cannot agree to deliver fixed scopes on hard dates. Either the scopes or the dates must be soft. We represent that softness with probability curve. For example, we estimate that there is a 95% probability that we can get the first ten stories done by the date. A 50% chance that we can get the next five done by the date. And a 5% chance that the five after that might get done by the date.
Refactoring is never a story. Architecture is never a story. Code cleanup is never a story. A story is always something that the business values. Don’t worry, we will deal with refactoring, architecture, and cleanup—but not with stories.
After the midpoint, if all the acceptance tests are done, QA should be working on the tests for the next iteration. This is a bit speculative since the IPM hasn’t happened yet, but the stakeholders can offer guidance about the stories most likely to be chosen.
Remember, the only failing iteration is an iteration that fails to produce data.
Business analysts specify the happy paths. QA’s role is to write the unhappy paths.
These two disciplines, double-entry bookkeeping and TDD, are equivalent. They both serve the same function: to prevent errors in critically important documents where every symbol must be correct.
The only way you get good at using a debugger is by spending a lot of time debugging. Spending a lot of time debugging implies that there are always a lot of bugs. Test-Driven Developers are not skilled at operating the debugger because they simply don’t use a debugger that often; and when they do, it is typically for a very brief amount of time.
Test coverage is a team metric, not a management metric. Managers are unlikely to know what the metric actually means. Managers should not use this metric as a goal or a target. The team should use it solely to inform their testing strategy.
You cannot write a function that is hard to test. Since you are writing the test first, you will naturally design the function you are testing to be easy to test.
So again, the bottom line from my point of view is this: There is no such thing as Agile in the large. Agile was a necessary innovation for organizing small software teams. But once organized, those teams fit into the structure that large organizations have used for millennia.
教练是一种源于教练气质的修炼方式——它是一种坚定的信念,相信自己和他人的能力、智慧和潜能,使教练能够专注于他人的优势、解决方案和未来的成功,而不是弱点、问题或过去的表现。
我们并不是说不需要专家的输入,但大多不太好的教练会倾向于过度使用专家知识,并因此减少了他作为教练的价值,因为每一次输入都是在减少教练对象的责任感。
许多低水平的教练常用引导性问题,这表明他们并不相信自己在做的事情。而教练对象会迅速意识到这一点,从而导致其对教练的信任度降低。教练宁可给教练对象直接建议,也不要试图操控他的前进方向。暗含批评的问题也同样应该避免,比如“你到底为什么要这样做?”
一个很少失败的有价值的现状问题是“到目前为止你已经采取了哪些行动?”以及“那个行动的结果怎样?”人们经常会想问题想得很久,但仅仅当被问及他们做了什么的时候才意识到他们实际没有采取任何行动。
有人曾经拿奥数题问数学家丘成桐,丘成桐表示自己不会做,也不值得做。相对于巧妙技巧来说,数学家更需要的是勤奋、眼光和思想 —— 而后者是有迹可循的,甚至可以模仿别人。
真实的工作中“诡计”没啥大用,智慧主要体现在明智的选择和开阔的眼界,而到最后只有勤奋才能让你走得更远。
牛和鹿在吃草或休息的时候倾向于面朝磁北或磁南。
整个美国的土地都属于“北美板块”,它是从东往西运动。西海岸是北美板块的前沿,在这里北美板块和太平洋板块相遇,形成一个俯冲区。北美板块在这里比较低的部分直接就被太平洋板块给碾压了,所以海岸线看起来很界限分明。而东海岸则是北美板块的后缘,就好像一个尾巴一样,拖着一些东西,经过泥沙积累,就形成了各个屏障岛。
那篇博客是一个叫摩根·杰克逊(Morgan D. Jackson)的昆虫学研究生写的,专门讨论的就是这种苍蝇翅膀上为啥有蚂蚁的图像。
杰克逊的文章说,这个现象纯属巧合。你看那个图案像蚂蚁,那是因为你作为一个人,总爱在任何东西上寻找意义和规律。其实那个图案根本没有意义。
搜索者的好奇,是看到一个什么东西,想要更*多*地了解这个东西。关键词是“多”。不是赞叹,不是喜欢,不是想把这个东西据为己有 —— 是这个东西给他传递了一个信号:背后还有更多有意思的事情,你值得了解!
一个人掌握的所谓关键信息,并不是土里埋着的一块金子,你只要使劲挖就能挖出来。关键信息是个很脆弱的东西,你用力过猛,就可能把它给破坏了。
如果你遇到有人要自杀千万要救,因为你救下这一次,他过后很可能就不想自杀了。如果你不幸想要自杀,千万要挺住!挺过这一关,你很可能就不想自杀了。
自从特斯拉的FSD推出以来,我在网上看了几十个小时的驾驶实测视频,都是出自我关注的五六个有话说话的特斯拉粉丝的频道,他们都很专业,实测视频不剪辑,尤其是自动驾驶系统出错或者处理不当的部分。
而我自己,并没有被选进FSD的测试,但使用Autopilot三年多,只要车上没有家人朋友之类的乘客,在高速上90%的时间,我都开启Autopilot,在城市路,超过半数时间开启。所以我看FSD视频的代入感很强,体验跟自己实测不会有质的区别。
Beta v9是纯视觉自动驾驶,就是只使用摄像头视频数据,完全不使用雷达数据。不久前推出了,我看了几天实测视频,打算写下一些感觉和对纯视觉自动驾驶这条路的理解和预测。几年以后回看,可以清楚知道自己当初错得有多离谱。
先说结论:纯视觉是一道自动驾驶绕不过去的坎。
聊聊雷达。雷达可以获得周边物体的位置,从而进一步计算与车的距离,物体的大小,相对移动的速度等重要的数据。如果用上激光雷达,对于一百米以内的距离的物体,可以获得更精细的数据。基本上,蝙蝠就是靠一套雷达系统在一个三维空间里毫无困难的穿行。那为什么自动驾驶光靠雷达不行?因为蝙蝠遇到红灯不用停,就算它想停,也不需要停在白线前。
雷达看不到颜色和很多例如地面的行车线等安全驾驶需要的信息。因此,自动驾驶还需要摄像头的视频数据。
于是,这就涉及到一个技术,叫传感器融合(sensor fusion)。就是要让雷达的数据和摄像头的数据交织在一起,供自动驾驶的算法使用。
传感器融合大致可以在以下三个层面进行:数据层(data)、特征层(feature)和决策层(decision)。

举个例子,这是我家附近一前一后的两个路口,两盏交通灯。雷达会检测到它们,但是不知道它们分别是红灯还是绿灯,甚至都不知道它们是否亮着。这时候需要跟视频数据融合。
先说决策层的融合,在这个例子里,雷达因无法判断红绿灯,无法做出走或者停的决策。而摄像头知道一红一绿,但是因为没有距离数据,不知道离我们近的路口的灯是红还是绿,也无法做出决策。
当然了,用透视原则,把图像的二维数据硬生生的“拉景深”,建模成为三维数据,然后通过换算,是可以单靠图像数据就估算出两盏交通灯离车子的距离的。如果结合图像前后若干帧,这种二维变三维的转化会更精确。如果用上多个摄像头的数据,就如同我们用两只眼睛,可以形成更精确的景深。特斯拉纯视觉就是这样从视频获得跟雷达类似的空间信息的。
于是,看来单使用决策层的融合,有些场景根本用不上雷达,靠的还是那个只有特斯拉才坚信的图像三维景深建模。
那我们来看看特征层融合。特征在机器学习里指的就是那些可以明确独立丈量的属性,在图像处理方面,例如形状、大小、颜色和距离等,在文字处理方面,例如词频、句子长度和用词感情色彩等。在感应器融合的分类里,特征层可以泛指在识别出物体之后的融合。
具体的特征层融合也有若干种不同的操作。
例如这个交通灯的例子,可以先从图像层抽取交通灯的边框(bounding box),然后对应相对坐标变换后的雷达数据,融合后便添加了距离数据。但很明显这种融合是假设以图像数据为主,补充雷达数据,假若图像数据没有检测出物体,雷达数据则并没有用上。
还有一种称为后融合的。雷达和图像的数据,分别通过各自的特征抽取,然后独立的得出物体以及它们的边框,然后通过启发式的数据组合,得出单一的数据输出,供自动驾驶系统使用。
还有其它的融合,例如先不做物体提取,而是把雷达和图像各自独立提取出来的特征导入深度学习,再单一输出物体提取。还有一种是把雷达数据转化为稀疏雷达图像数据,然后分别针对大型物体和小型物体进行两种不同的融合。
还有很多其它的,但是魔鬼在细节,在下面我会更详细的阐述所有在特征层的融合的硬伤:雷达和图像在物体甚至只是特征的提取上,可能存在不同意见。
那数据层的融合呢?这层的融合在同种类(homogeneous)的传感器之间是比较可行的,但要融合雷达和摄像头这两种传感器的数据就不太直观了。在没有任何对数据的提取的前提下,数据层有的只是0和1。
另外值得一提的是,很多传感器都有因应该类型传感器专门优化的数据压缩算法,很多是有损压缩。但数据层的融合,要求在融合前并不能进行这种压缩。这对于带宽和处理速度都是高一个数量级的要求。
既然传感器融合如此困难,那为何不干脆不做融合,各传感器自己利用深度学习后的模型,给出自己的判断,然后谁更可靠,就听谁的。例如在停红灯这件事情上,我们听摄像头的,不听雷达的。但如果是汽车前方有行人的场景,我们听雷达的,不听摄像头的。可行吗?
这就回到“自相矛盾”这样一个千古难解的哲学问题。
给你讲个故事。那天,我约了围棋手柯洁,准备跟他大杀几局,当然我是打算用阿法狗作弊的。但结果却忘了带上阿法狗。只带了进攻可以与阿法狗匹敌的矛狗,号称无坚不摧;和另一只防守同样可以与阿法狗匹敌的盾狗,号称牢不可破。于是,我是基本不担心赢不了柯洁的。
我们坐下来,才下第一子,我就发现事情并不是想象中那样。因为矛狗建议我下这里,但是盾狗却建议我下那里。我现在要用自己仅有的棋力,去判断哪个建议更可靠。
只要一涉及到需要人来最终作一个决定,或者在自动驾驶的领域,涉及到需要程序员或者程序员写的代码来最终作一个决定,这就是整个系统的不可逾越的一块短板。阿法狗的厉害之处,就是不需要它的发明者在下棋的时候参与任何决定,如果人类硬是自作聪明的说阿法狗你其它子都下得可以但这一子太烂了,这一子按我的判断来下,估计结局不会太好。
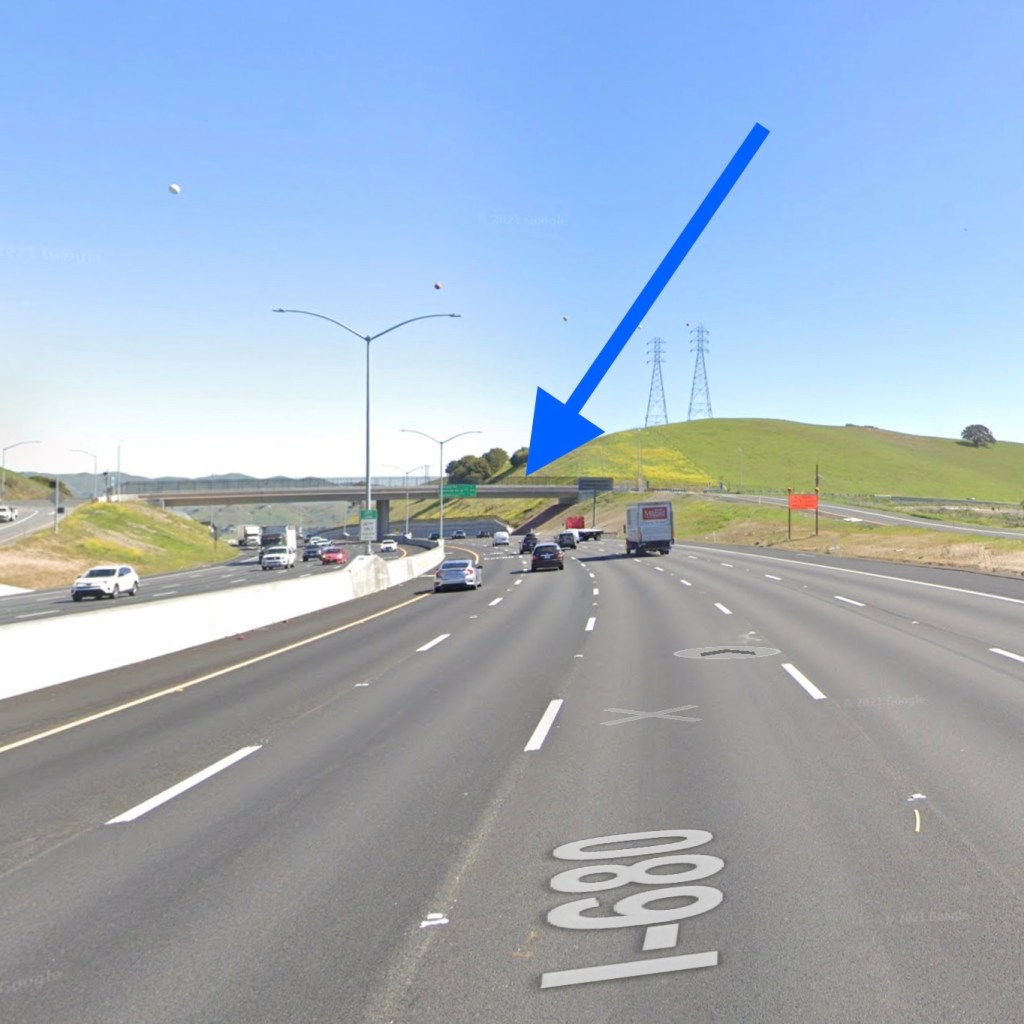
在湾区的这一段680高速上,Autopilot经常会突然无故减速。
留意箭头处,其实是跨在高速公路上面的桥。雷达其实分辨率非常低。而且有个致命的弱点是,垂直方向的静止物体的分辨率更是惨不忍睹,对于这样的一座桥,雷达难以确定它离地面有多高,只知道是一个在几百米处的障碍物。而摄像头却可以比较确定前面的这是桥。矛狗和盾狗的判断出现分歧,你听谁的?当然老司机都知道不能听雷达的,高速公路上谁会放这么大一块障碍物?!这种情况没有必要减速。

但是之前几起事故都是因为图像数据没有正确分辨白色货柜车与天空而做出误判的。我们比较肯定当时就是错听了摄像头而没有听从雷达。老司机就会理直气壮的说,那如果摄像头做出误判的时候,当然就要听雷达的啦。就如同理直气壮的说,当矛狗做出误判时,我们当然要听盾狗的啦。老司机你这么牛,那不如整盘棋交给你下。
上述事故,关于改进,方向有二。如果我们决定只靠摄像头,那就得在纯视觉方面下狠功夫,老老实实的学会把白色货柜和天空分清楚(这恰恰正是特斯拉当前逼自己走的路);但如果我们决定靠雷达,就得加入更精准的雷达,例如激光雷达。
但是,无论再厉害的雷达,我们一方面知道单靠雷达不能作决策,因为雷达看不到颜色和标识,神级雷达也还是需要摄像头的参与。不幸的是,另一方面这个“猪队友”摄像头总是会在判断物体或者特征的时候偶尔出错,从而造成了一定要判断该听谁的。
要减少甚至避免队友之间的不同步,很显然,当务之急是给这个猪队友搞地狱式的集训。集装箱和天空都分不清,单打基本功都这么烂,还训练什么攻守联防、双剑合璧?图像处理的机器学习要改进到一个极端可靠的地步,要不,安装了激光雷达还是白搭。
于是,可以理解为什么特斯拉从最近几个月开始,下生产线的新车,连雷达都不装了。也可以理解,为什么特斯拉觉得一天不把图像处理的人工智能搞完美,都一天不需要装激光雷达。
接着,来讨论圈子里一个极具争议的话题:自动驾驶到底需不需要激光雷达?
上面我们得出了一个洞见,只要有两个传感器,要100%可靠融合,就必须在每个特征和物体的提取上,雷达和摄像头的判断是100%一致的。例如,雷达说看到那里有个行人,同时摄像头不能说看不到那里有个行人,否则无法融合。
那问题就来了。很多人建议加上激光雷达,是因为这样在黑暗或者一般视野受阻的时候,还能检测到一些摄像头无法发现或者清晰分辨的物体,但刚刚我们说了,如果激光雷达说有人,但摄像头说“啥?人在哪里,我看不到”。这样两种传感器的数据是无法融合的。
你说,好了好了,说来说去不就是个融合不能完美嘛,咱真的就别融合了。激光雷达数据这么可靠,到了要决定听谁的,就只听激光雷达的吧!
好,我们刚好来到一个路口,没有交通灯,激光雷达说可以右拐,是安全的。我们刚右拐,咔嚓一下给警车拦下来了。警察说你没看到不许右拐的标志吗。于是你觉得,事情没有绝对,这种情况明显是摄像头说了算,写在代码里就好了。于是,第二天我们又来到这个路口,不能右拐的标志撤掉了,摄像头这次说可以右拐了,咔嚓一下撞到路人了,虽然激光雷达也看到路人了。你觉得,没有不许右拐的标志这种情况,明显还是雷达说了算,不是之前就写好在代码里了吗。。。OK,这么牛,你行你上,都别搞什么机器学习人工智能自动驾驶了,你能想到的一一都写在代码里让它按你的意思运行就好了。
其实,阿法狗躺赢李世石那天,它就已经清清楚楚的告诉世人,深蓝赢卡斯帕罗夫的年代过去了,人类如果希望人工智能可以干得比人漂亮,就请放弃偶尔还想写段代码帮人工智能一把的天真想法。到了阿法狗零的出现,证明了不要说人,连人类棋谱都是一种拖累。老司机有毒。
我同意激光雷达加上一些启发式的算法,的确会对提高自动驾驶的质量提供帮助,尤其是现阶段猪队友实在是弱鸡到不行。短时间内把自动驾驶提高到可以很好的辅助人类司机的水平,跟让自动驾驶超越并替代人类司机,是两个很不同的目标。但我坚信最终能超越并且替代人的那套自动驾驶系统,绝对会是人类智慧的结晶,但不是人类驾驶智慧的结晶,里面不需要一丁点人类在驾驶这件事情上的经验。
我认为激光雷达只有在以下几种情况,在自动驾驶领域能真正有用起来。
1)纯视觉人工智能靠图像推断出类似激光雷达的数据,关于物体的大小、距离和车速,然后用真的激光雷达的数据去做同类传感器的数据层融合,校准纯视觉的结论。这相当于在训练纯视觉人工智能的时候,提供优质的三维数据标签服务。那几台安装了激光雷达的特斯拉估计就是干这个的。但这些校准都还是围绕着摄像头能抽取的物体,对于摄像头“看不到”的物体,不存在校对。
2)在矛狗和盾狗出现分歧时,作出判定应该听谁的,不是程序员,也不是程序员写好的代码,而是另一个经过机器学习的模型。激光雷达和摄像头做出的决策是这个人工智能的输入,输出则是最终的决策。用神经网络来实现底层的决策融合。当前在雷达领域的工程应用,比较常用的是卡尔曼滤波算法(Kalman filter),它能自动决定该听谁的,但它只是传统的人类的算法或者概率方法(Probabilistic method),并不涉及神经网络。这是“深蓝”的路,再努力走下去也走不出一个阿法狗。
3)异类传感器在数据层的融合能有突破。就是激光雷达数据和图像数据在原始数据阶段可以完美整合,就如同数据直接来自单一个传感器。甚至在硬件上就只是单一个传感器(相当于一个内置激光雷达的摄像头,或者相当于一个内置摄像头的激光雷达),输出单一组更可靠的三维图像数据。就如现在很多封装了加速器、磁感和陀螺仪在一个IMU里面的设备一样。这种突破我暂时无法想象。但我认为这应该是走非纯视觉路线的努力方向。
归根结底,或许我想说的是,在整套自动驾驶解决方案中,甚至在帮助人工智能得出这套解决方案的解决方案中,我觉得启发式(heuristic)的占比是越少越好,最好是零。
特斯拉的纯视觉自动驾驶可能会遇到什么瓶颈?
1)当前车上装备的电脑运算速度可能不足以支持纯视觉模型所需要的运算量。只是差一点的话估计还可以通过优化勉强将就着用。担心的是差的不是一个数量级的。
2)万一当前深度学习领域的浑身解数都使上了,但是就是打不通这一关。这个结果是比较灰的,如果真有这一尽头,现在离它还很远很远。
特斯拉现在v9的几个重点的挑战:
1)round-about之类的大小转盘。
2)从小岔路无保护(没有停牌没有交通灯)的情况下转出快速车流的主干道,尤其是左转。这是人类老司机也会特别小心和头痛的场景。
3)地图数据有错漏。例如地图说前面路口是三车道,需要直行就走中间道。但是实际快到路口发现其实只有两车道,那应该走左车道还是右车道,那就全凭自动驾驶“见机行事”。其实,这也是一种数据融合,幸好这种不一致很好处理,地图数据只是参考,永远都应该以“眼见为实”。
v9应该开放给更多的测试者吗?
虽然我很希望尽快能亲自测试v9,但现在还不应该扩大测试人群。从采集训练数据角度,现在的测试人数已经足够特斯拉现阶段使用了。从测试视频看,如果不是一条直路走到底的那种城市路,基本能做到大约平均3到5英里无需接管。再长的路线就会出现处理不好的情况,偶尔需要接管。
我觉得至少做到平均30英里无需接管,大约就是湾区民众上班的距离,才应该放开测试。估计2022年底能做到。然后做到大约300英里无需接管,就可以开放给所有人。较当前两个数量级的进步,我很怀疑现在装备的电脑硬件能否继续应付。
现在再扩大测试者数量,会混进一些蠢人,他们会干一些蠢事。
最后几点声明:
1)我不在特斯拉工作。也没有参与自动驾驶的项目。此文的观点纯粹是基于一些对机器学习的粗浅认识的理解。欢迎内行人士指出错漏。
2)持有一些特斯拉股票,所以文章不可能绝对中立,虽然我已尽力。
3)纯视觉自动驾驶只是其中一条路,很高兴有其他公司在其他方向出钱出力。多样性是成功进化的必要条件。
4)人类文明自从不再需要围捕猛兽以来,人们每天都必须冒生命危险去做的事情已经不多了,除了个别有献身精神的行业,例如消防员和警察等。对于开车或者坐别人开的车,很多人其实只是想从A点去到B点而已,没打算要冒险。
5)在某种意义上说,我们都在等待的是自动驾驶的阿法狗时刻。一旦超越了人类,就再也不会回头,一骑绝尘。那时候的人,会感叹人类历史,曾经会有让人类自己来开车这么野蛮愚昧黑暗的时期,而且竟然还持续了上百年。
参考文献:
Berrio, J. S., Shan, M., Worrall, S., & Nebot, E. (2021). Camera-LIDAR Integration: Probabilistic Sensor Fusion for Semantic Mapping. IEEE Transactions on Intelligent Transportation Systems, 1–16. https://doi.org/10.1109/tits.2021.3071647
John, V., & Mita, S. (2021). Deep Feature-Level Sensor Fusion Using Skip Connections for Real-Time Object Detection in Autonomous Driving. Electronics, 10(4), 424. https://doi.org/10.3390/electronics10040424
Mendez, J., Molina, M., Rodriguez, N., Cuellar, M. P., & Morales, D. P. (2021). Camera-LiDAR Multi-Level Sensor Fusion for Target Detection at the Network Edge. Sensors, 21(12), 3992. https://doi.org/10.3390/s21123992
中国汽车技术研究中心有限公司. (2020, November). 中国自动驾驶产业发展报告(2020)(自动驾驶蓝皮书). 社会科学文献出版社.
他们必须坚信,把时间用于帮助他人、制定计划、教练辅导和类似的工作,是他们的职责,而且他们必须把通过他人完成任务作为自己取得成功的关键。
例如,一位投资银行的经理,可能亲自组织一项复杂的交易,而不是支持下属去做,他喜欢向人们展示自己在这方面的专长。另一种情况是,当他们对下属的工作方法感到不满时,便亲自去做,这在无形中产生了与下属的竞争。
当然,沟通需要占用很多时间,很多一线经理习惯将时间用在“做事情”上面,而不愿意花时间与人沟通,这将导致由于缺乏充分的信息做出草率的工作布置。
领导力在第一个管理层级出现问题的明确信号是员工感到压力很大。当员工感到不知所措、抱怨上级没有足够的支持时,这表明经理缺乏这个岗位所需的关键技能。
不应该把下属提出的问题看成是障碍。
不应该补救下属的工作失误,而是教会他们如何正确去做。
