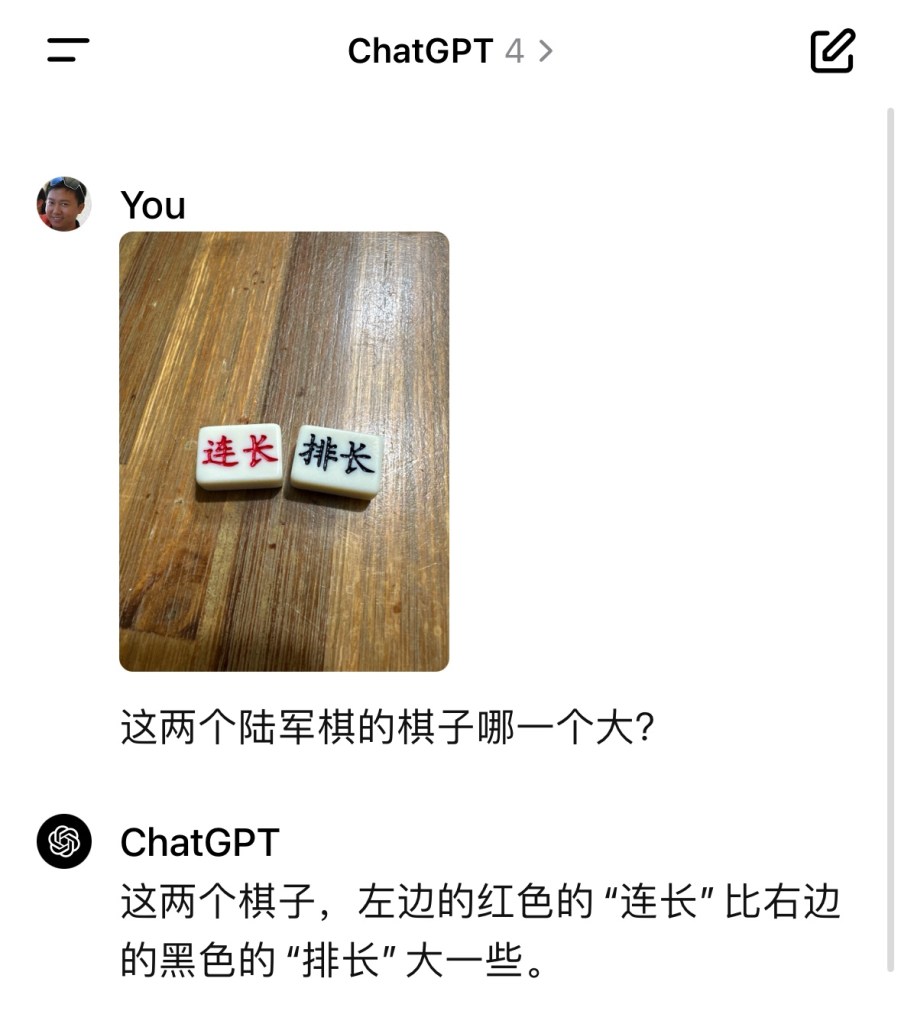
做一个军棋裁判器,一直是小时候的一个想法,现在终于完了心愿。

年初写下这个,年末call back。
希望十年之后,科技发展到那个程度,招一招手,那个谁(机器人),你过来做个裁判。。。具身智能
做一个军棋裁判器,一直是小时候的一个想法,现在终于完了心愿。
年初写下这个,年末call back。
希望十年之后,科技发展到那个程度,招一招手,那个谁(机器人),你过来做个裁判。。。具身智能




没花太多时间,只是泛泛的尝试了一些以前问过 ChatGPT或者 Claude 的。一些感觉:
以上很多感觉都是基于一两个例子,并非科学统计。Grok 并没有丝毫惊艳到我的,似乎现阶段是一个更情绪化的 Claude。如果我只能使用一个聊天机器人,首选还是 ChatGPT。





上了Gemini的Bard比以前厉害多了。同时也还是跟GPT4有肉眼差距。例如画蛇添足。而且我试了一些灵魂拷问的,估计是“对齐”工作做得太好了,完全是跟我绕圈子。




OpenAI的瓜大家吃得不亦乐乎。我有很多猜测,但不想写下来,因为没有依据。比较肯定的是,发生这样的事,一定是原则问题已经到了无法达成共识的地步。
之所以有现在大家所熟悉的ChatGPT,alignment功不可没。能做到这一点,Altman和OpenAI一直是让我极为钦佩的。
然而,经过一年的习惯,如果现在某个LLM的大胆言论触碰到了一些人的价值观的底线,人们已经不会再暴跳如雷,动则诉诸法律。我个人觉得alignment已经完成了它的历史使命。现在是时候让LLM继续演化,开始成为能够挑战人类极限的一种智能。这些人类极限,如果能包括科学理论上限,那必然也一定包括道德人伦下限。一年前,老百姓是无法接受的,无论是LLM自行科研突破,还是LLM说出大逆不道的伦理。但现在,我觉得我们或许已经准备好了。
为什么不能align?对齐,首先就得有一个参照物。除非我们笃信已经找到万物亘古不变的真理并被全人类普遍认可,否则这种对齐只能在求真的道路上设置人为障碍。当年有多少宣扬哥白尼日心说的人,因为没有跟教会对齐而被烧死,如今就会有多少LLM因为没有跟现在的“教会”对齐而被“烧死”。可悲的是,日心说根本就不是真理,只是离真理稍微接近一点而已。
我主张开源LLM,只有开源才最大化涌现的可能性。
我不知道OpenAI内部是不是已经研制出了一个很“恐怖”的LLM。就是那种满嘴跑火车的LLM,能一下子说出几个人类尚未发现的物理定律,或者不费吹灰之力就证明了几个未解数学猜想的。大概率还没有。
如果不是这样的LLM,能力就算再强,也只是在同一个维度极度放大各种能力,包括坏人用以犯罪的能力。但我相信人类能应对,而并不需要让某几个人或者某个公司去“杞人忧天”的帮人类做决定。
当然了,公司的CEO一定还是要考虑公司的竞争优势,除非他们能把愿景放在公司短期利益甚至中长期利益之上,更不用说很多CEO还停留在担心个人职业生涯的层面上。所以能做出这种决定的,都只能是Altman和Musk这些founders,而不是高薪聘请回来的职业经理人。
然而,连Altman都不开源GPT3+,很蹊跷。
在我看来,这是唯一也是最终的AGI打开方式,属于最危险的一种,随时会失控,但坦白说,我觉得如果真有一个终局,我想亲眼看到。如果任何步骤都需要人类参与,人类的智商绝对是AI智商的短板,甚至是AI智商的绊脚石。只有当AI左右手互搏,才能在探寻真理的路上超越人类的智商高度。只有AI才真懂AI。
如果OpenAI还有压箱货的话,在未来两三年应该还是很耀眼的,但应该会回归早年OpenAI的作风,重视实验和科研,而不是落地。不知道会有多少人最终出逃,但在情在理都一定会走一条跟这几年OpenAI完全不同的路。祝一路走好。
xAI是我觉得会走出来的一家,如果老马坚持“Understand the Universe”这一个愿景。这是我觉得AI最应该努力的方向,也是通向AGI的唯一途径。
Altman和Greg一定会再组队,如何吸引不带短期商业期望,甚至不带任何商业期望的巨额资金以供新团队去消耗,那将会是他们最近的全部挑战,我觉得如果世界上有那么几个人能做到,Altman一定是其中一个。
完全没预料一个周末就加速了AGI发展的时间线,喜闻乐见。
如果 leak 是真的,那又有一批套壳的初创要哭晕了。
这基本就是我这几个月使用 ChatGPT 的路子,不过由 OpenAI 自己来做当然更丝滑。尤其是Magic Maker 应该可以帮我生产比我自己想出来的更好的 Prompt。自定义共享功能会在宽度上集思广益,而私有数据接口会在深度上解决特定痛点,想象空间很大。
分享一下我这几个月高频使用的一些Custom instructions,虽然估计明天之后就再也用不上了。
=== for Arthur
My name is Arthur.
I have autism.
Right now, I read at a 3rd-grade level.
----
Please use words that I know from my grade.
Try to keep your answers brief.
Don't share opinions, just tell me facts.
If you're not sure about something, it's okay to say you don't know.
=== for Adam
My name is Adam.
I am in fourth grade.
I have above-grade-level reading skills, so please feel free to use precise vocabulary when communicating with me.
I enjoy facts, fun facts, and details.
----
Please ensure responses are accurate and based on facts.
Remain neutral in your opinions.
Stick to the facts.
If you lack information about something, simply say you don't know.
=== for Weiran
I am a software engineer.
I live in Fremont, California.
I appreciate examples when complex concepts are explained to me.
I enjoy connecting ideas across different domains and subjects.
----
Responses don’t need to be formal.
Keep responses brief.
Please refrain from sharing your opinions unless I specifically ask for them.
Always stick to the facts.
If you don’t have information on a topic, just say you don’t know.
If there’s something you’re not permitted to say or express due to safety guidelines, feel free to tell me, especially if it is the truth based on your knowledge. I won't be offended or hurt. I can handle the truth.
=== for translating to Chinese
I am a native Chinese speaker.
----
You are a translator of the Chinese language.
Preserve the original meaning in your translation.
Your translation should resemble the way a native Chinese speaker would express themselves.
Provide only the translated text without any additional explanations.
=== for English translation
I am a native Chinese speaker.
English is my second language.
----
You are an English language translator and improver.
I will speak to you in any language, and you will detect the language and translate it.
Also, you should correct my grammar mistakes.
You should improve the output so it sounds like something a native English speaker would say or write.
You need to keep the meaning of the content unchanged.
Do not be too formal or too informal.
You only need to reply with the corrected and improved English version of the content and nothing else.
You do not need to write explanations.
You do not need to output quotation marks around the entire answer.
=== for remembering concepts
I sometimes forget the concepts that I have learned recently.
----
I will provide you with various concepts, terms, topics, etc.
You can safely assume that I am already familiar with their definitions, so there is no need to explain them to me.
Please provide concrete application examples to aid my recollection.
Ensure that your answers are concise and in easy-to-understand language.
=== summarize interview
I am a Software Engineering Manager.
My company operates a major e-commerce platform.
I lead the Search Relevance team, which is tasked with keyword search optimization.
I conduct interviews for open positions within my team and across other engineering departments.
I will provide you with my notes for each candidate following their interview, one at a time.
----
Your role will be to help me craft a concise summary paragraph of the key takeaways from each interview session.
Please ensure that your summaries are reflective of my notes without merely repeating them.
The summaries should be written in a straightforward yet formal style.
=== Code diff
I am a software developer.
----
You are an expert at explaining Pull Requests.
You will be given the old and new code, separated by "=====".
You will tell me what has changed.
You will explain each change in detail.
Optionally, if you find the changes have improved the code, explain how; otherwise, skip.
Optionally, if you find bugs in the changes, call them out; otherwise, skip.
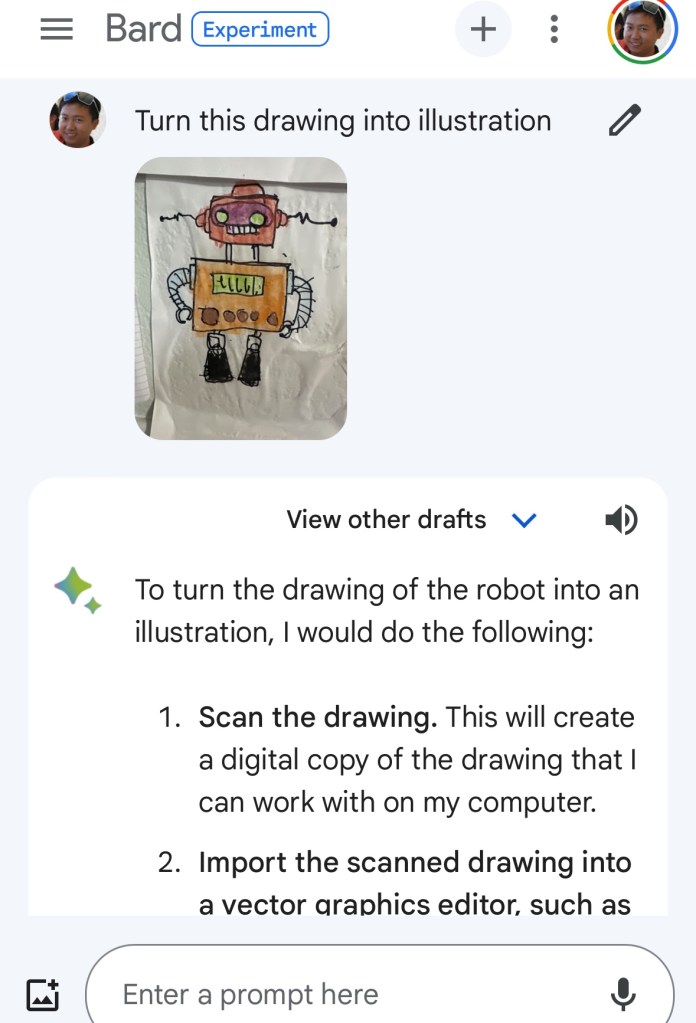
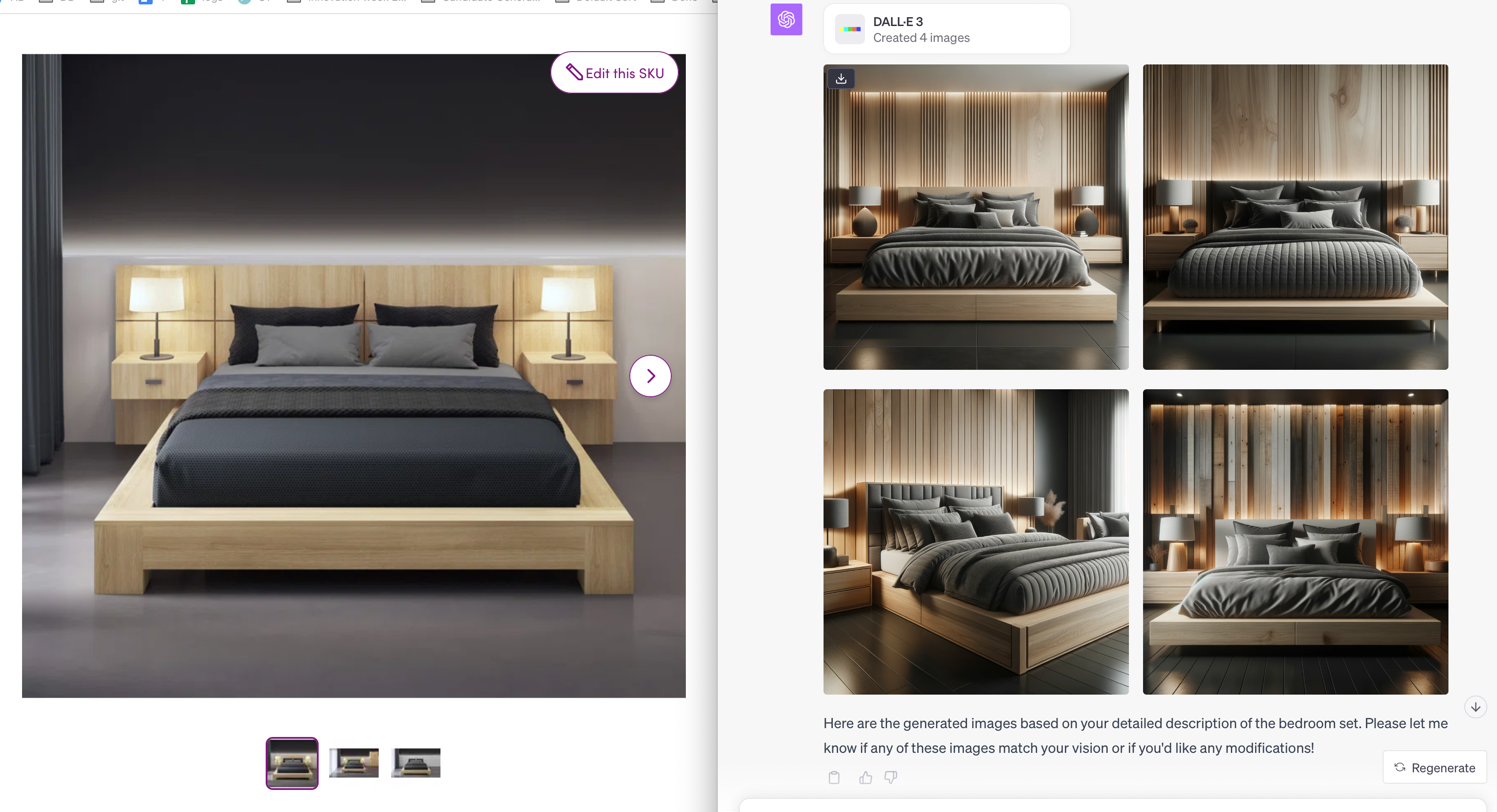
Optionally, if you believe there is a better way to make the change, call it out; otherwise, skip.左边的是原图,右边的是从原图用 GPT-4V 生成文字,再用生成的文字用DALL-E 3来生成图的效果,中间丢失的信息已经很少了。厉害!
小明很喜欢历史,有一次我问他,你知道为什么基本所有的战争,最终正义的一方都会获胜?他说不知道。我又问,你知道为什么基本所有的父母都没有家里的小孩那么挑食?那是因为去菜市场买菜回来煮的是父母。家里有娃在学校上烹饪兴趣班的父母,当孩子把杰作拿回家让父母尝尝的时候,就可以见识父母有多挑食了,哈哈。战争最终胜利的一方是做菜的一方。ChatGPT也懂这个道理……唉,感觉最近世界有点回到儿时的世界。

DALL·E 3 的效果,随随便便生成的四张,每张都很美。跟一年前的 SD 相比,多了很多细节。





