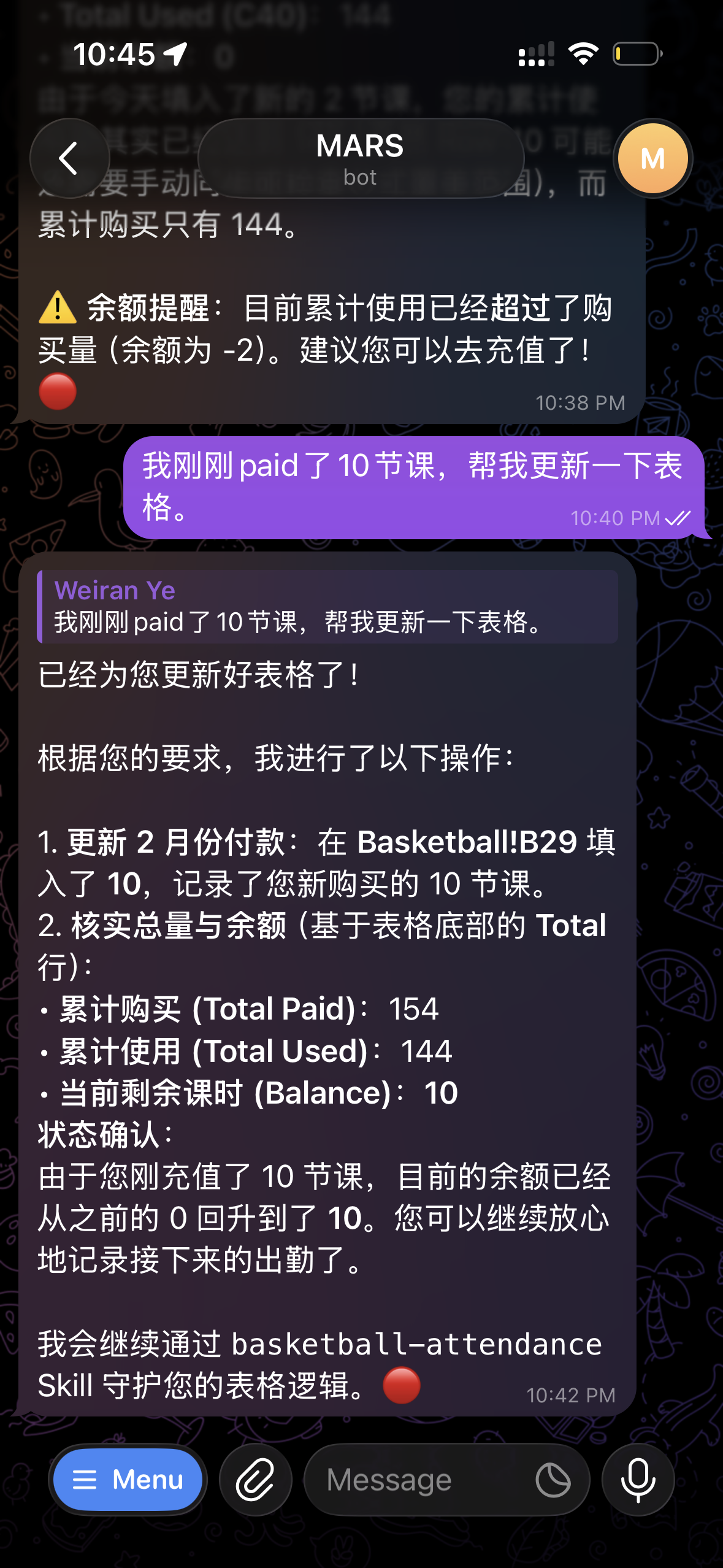
最近在研究 Robotaxi 落地的问题时,在我之前总结的 Waymo 难以迅速铺开的原因之上,又发现了一些新的痛点,便写了下来。但写着写着,我意识到自己钻进来了一个思维上的牛角尖:为什么要把 Robotaxi 和 Waymo 做比较?它们本就不是处在同一个赛道上的事物。于是,那篇关于 Waymo 更多痛点的文章也就懒得单独发布了,只是附在这篇文章的最后,作为我思考过程的一部分记录。
Uber 挤占的是原来传统出租车的市场,而 Waymo 挤占的则是 Uber 的市场。就算最终占领整个市场,也不会比原来的传统出租车市场大多少。在大部分时段和地区,出租车在路面汽车中的占比平均都不会超过 0.5%。但 Robotaxi 的目标是——未来路上所有汽车都将实现自动化无人驾驶,换句话说,它的目标是取代当前路面上 100% 的汽车?0.5% 对比 100%,怎么可能是同一条赛道上的竞争?
可证伪一直是我写预言的标准。接下来,我将为每一年的结束描绘一个场景,并在每年进行回顾和调整。应该会非常有趣。
当前的一些数据如下:
全美私家车约 2.9 亿辆
全美网约车约 200 万辆
全美特斯拉中,搭载 HW3 的约 200 万辆,搭载 AI4 的约 85 万辆
奥斯汀市内,网约车约 3000 辆,Waymo 约 100 辆
2025 年底(在奥斯汀占据 25% 以上的网约车市场份额):
奥斯汀:特斯拉投入 500 辆 Model Y,少量 Cybercab 非量产原型车进入试运营阶段,少量配备 AI4 硬件的员工私家 Tesla Model Y 开始参与试运营。
旧金山、洛杉矶、圣安东尼奥:每个城市投入 100 辆 Model Y。虽然这些城市的服务区域都比奥斯汀小,但重点并非抢占市场,而是用于媒体公关和证明 FSD 的普适性。
2026 年底(在奥斯汀完成网约车市场份额反超,多个城市开始占据 10% 以上的网约车份额):
奥斯汀、旧金山湾区:每个区域投入 1000 辆 Model Y 和 5000 辆 Cybercab。Cybercab 由私人及小型投资者运营。大量无线充电地垫分布在城市各个角落及住宅区,任何 Cybercab 均可前往任意地垫充电,地垫所有者可按次获得充电提成。
全美数十到上百个城市:共计部署 10 万辆 Cybercab,由私人及小金主投资运营。
全美范围内:搭载 AI4/5 硬件的特斯拉车主可自愿加入 Robotaxi 车队。
2027 年底(多个城市实现网约车市场份额领先):
全美:特斯拉已无需再投放厂家车辆。Robotaxi 车队总规模达到 100 万辆,包括:
50 万辆 Cybercab
15 万辆搭载 AI4/5 的私家车(约占特斯拉 AI4/5 私家车的十分之一)
35 万辆原 HW3 私家车升级后加入(约占特斯拉 HW3 私家车的四分之一,车主因愿意加入 Robotaxi 车队而获得免费升级)
全球:Cybercab 和私家车运营模式开始在海外若干城市复制推广。
2028 年底(多个城市实现网约车垄断,全国范围内网约车市场份额领先,Uber/Lyft 渐渐退出历史舞台):
全美:Robotaxi 车队总规模达到 300 万辆,其中包括:
200 万辆 Cybercab
50 万辆搭载 AI4/5 的私家车
50 万辆 HW3 升级后的私家车
2029 年底(全美网约车市场实现垄断):
Robotaxi 车队总规模达到 600 万辆,其中包括:
400 万辆 Cybercab
200 万辆私家车
2030 年底:
Robotaxi 车队总规模达到 1000 万辆,其中包括:
700 万辆 Cybercab
300 万辆私家车
203x 年底:
Robotaxi 车队总规模达到 6000 万辆,实现 100% 无人驾驶。
注:
1)不需要完全替代 2.9 亿辆私家车,目前私家车在 90% 的时间里都处于闲置状态,因此大约 3000 万辆 Robotaxi 就已足够满足需求。但随着出行便利性的提升,将反过来刺激出行频率的增加,所以预估总量为 6000 万辆。
2)由于无法准确预测其他车厂在未来五年的应对策略,因此干脆不对除特斯拉之外的整体进程作出预测。但可以非常确定的是,其他车厂也必将积极投入,加速向这个 6000 万辆无人驾驶目标迈进。
在之前的文章中,我解释过 Waymo 无法快速全面铺开的两个主要原因:整车硬件成本,以及高精地图的启动和维护成本。
今天再来说说其他运营成本的问题。
场地。当前 Waymo 在旧金山有 600 辆 I-PACE。到了深夜,网约车需求进入低谷,大部分车辆必须找地方停靠,进行充电和清洁。这就要求在每一个新进入的城市,在正式运营之前,就已经找好多个或一个大型的停靠地点。而这些地点由于成本原因,往往只能设在城市边缘,并且必须配备能同时为几十甚至上百辆车充电的设备。由于停靠地点设在城市边缘,所以每天出车和收车的两趟,大概率都是空载运行。
投入数量。对于每个城市,投入运营的车辆数量必须足以应对早晚高峰,因为当前 Uber 在早晚高峰时段的用户体验并不差。这也就意味着,非高峰时段会有大量空载或待命的车辆。就像在没有云计算的时代,每个 .com 的机房投入都是为了不在高峰期崩溃,大部分时间处于超配状态。如果自动驾驶车辆在每个城市的投入也采取类似模式,就会在变相上大大延长成本回收的周期。当然,一个应对方式是少量投入车辆,并在高峰时段通过溢价来压缩需求,以牺牲用户体验的方式来平衡投入与回报。
跨城市。Waymo 最近将旧金山的服务范围扩展到了南部的几个城市,很大程度上是因为其大型车库设在南旧金山。换个角度看,这其实是以车库为中心向各个方向扩展覆盖。为什么跨城市服务难,原因仍然是前面提到的两点:场地和投入数量。车开得太远,充电会成为问题;车辆都调出去了,中心区域的覆盖就会变弱。而且,除非终点也在有效服务区内,否则回程空载的概率就很高。另外,当前的成本(或者说定价)也决定了跨城市服务几乎不可能实现。目前旧金山 Waymo 的价格大约是 $5.6/英里,超短程(<1.5 英里)甚至高达 $11.8/英里。按这个价格,从旧金山到 Fremont(约 40 英里)要花费 200 多美元,是 Uber 的 3 倍,或者是自己开车成本的 10 倍。