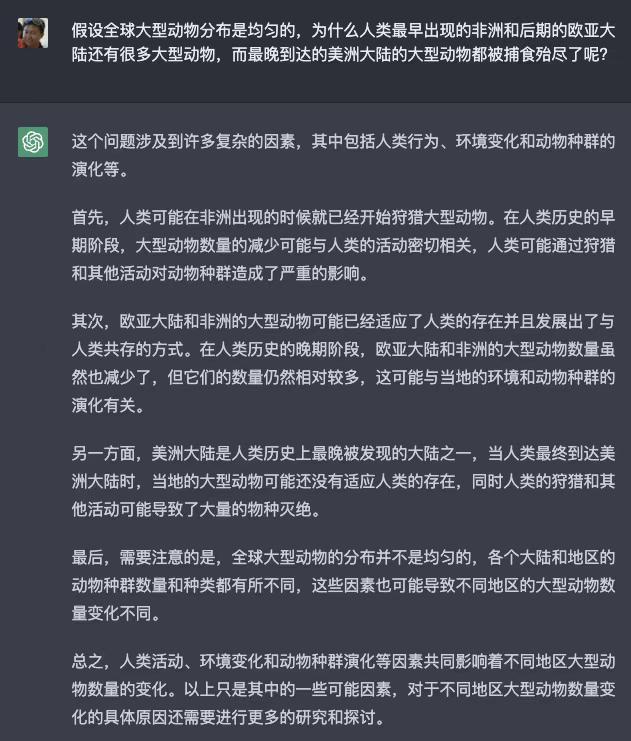
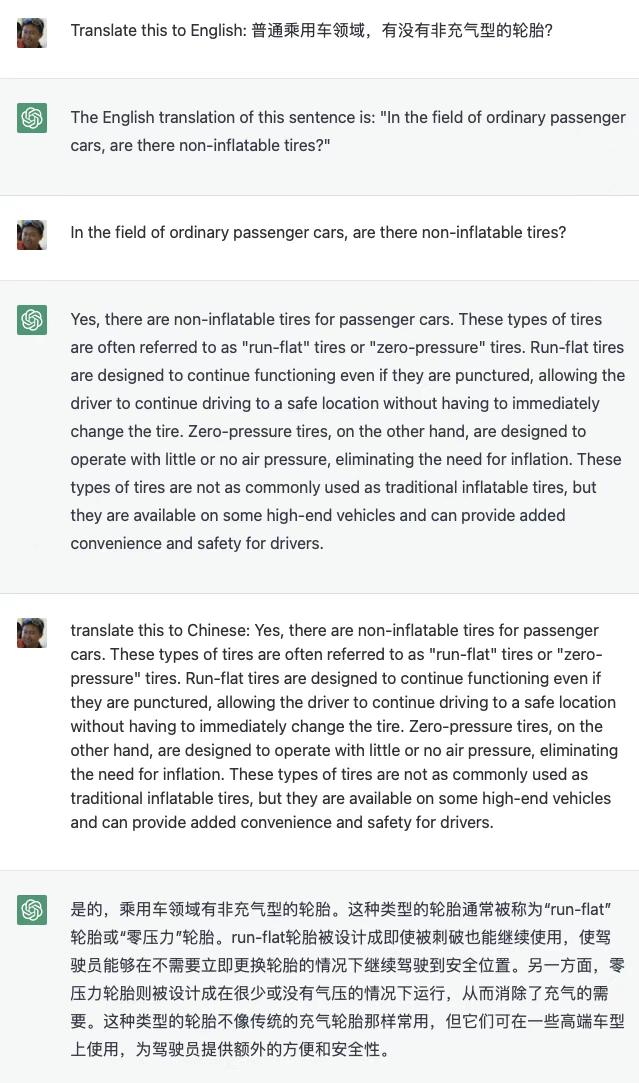
InstructGPT 有 99.9%的训练数据是英语,openai 团队自己也对模型的语言泛化能力感到惊讶。我想试一试它对于直接中文问答(图一二三),“中-英-中”后台(图四五六),和“人工中英中”(图七八九)的区别。结论1,ChatGPT 是用模型自身的泛化来对话,真的没有翻译的步骤。结论 2,如果你直觉觉得要问的问题,英语资料会比较多或者比较准,可以用我的这个 prompt。结论 3,在这么少的中文训练数据的情况下能用中文如此作答(注意不是针对问题靠英语资料翻译出来的),证明模型通过训练数据“学懂了”英文文字背后的知识,而并不是单纯的在作答的时候按着前后文用概率生成下一个在中文语言下概率高的词/::! 达到了一定规模的数据关系终于产生了知识的涌现。